Data and Web Scraping
Did you know that data has already surpassed the value of oil which is one of the most valuable resources of modern time? Yes, and this is no surprise as most modern businesses run on data. The five most valuable listed firms in the world– Amazon, Alphabet (Google’s parent company), Facebook, Apple, and Microsoft — all rely heavily on big data.
However, unlike oil, you do not need heavy machinery to “mine” data. Websites, where you can get valuable information, are easily accessible through the internet. Any average person that has the right tools and decent knowledge of how to use the internet can benefit from it.
There are various ways to obtain data from any website. For starters, you can simply visit any website, browse, and just copy and save the information you want on your local hard drive. That sounded easy, but what if you have to browse hundreds or even thousands of individual pages to extract the data you want? Doing it manually doesn’t make sense anymore, and as they say, modern problems require modern solutions.
Web scraping is one of the easiest and efficient ways of obtaining data from any website. It is a technique to fetch any amount of data from a certain webpage then save the extracted data to local storage or a database. In general, it is a program or software that can simulate human web surfing and collect specified pieces of information from different web pages.
In this article, we will show web scraping in action. This is a beginner’s guide on how you can put web scraping to good use. And what website would be the best one to demonstrate the effectiveness of web scraping? As a stepping stone, we recommend one of the big five companies in the US- Amazon. The company is known for its technological innovation that has disrupted well-established industries. It is also the world’s largest online retailer which means we can gather a lot of information that can be of great value to anyone.
Why scrape Amazon?
Amazon is an eCommerce platform that contains massive data that is important to online retailing. People love scraping various data on Amazon because they are easily obtainable and benefit a lot of businesses. Like for instance, you can collect data on competing products to help your company develop a genuine strategy and make the right decision. You can also gather information on product reviews for your own products or a competing product to easily evaluate its performance and do a comprehensive analysis on how you can improve customer experience or even the product itself.
What is ProxyCrawl and why use it to scrape Amazon?
Before we can start scraping, of course, we need to build our “scraper”, and if you do not have the necessary skills to write a code yourself from the ground up, do not worry as we have the perfect product that can be used for any web scraping needs. ProxyCrawl offers an easy to use API which we can utilize as the foundation of our scraping tool. The Crawling API will allow us to easily scrape most websites and it will protect our web crawler against blocked requests, proxy failure, CAPTCHAs, and more. ProxyCrawl’s products are also built on top of thousands of residential and data center proxies worldwide integrated with Artificial Intelligence which is guaranteed to deliver the best data results possible.
How to scrape product reviews with Node.js
For this article, we will build our scraper using Nodejs to fully take advantage of ProxyCrawl’s API-based structure. This simple project will be able to scrape product reviews from a list of Amazon URLs efficiently and save that scraped data straight into a CSV file.
To make this easier, we have prepared a list of things we need to accomplish this project.
1. A ProxyCrawl account – This is needed to use the API for our project. Upon signing up, you will be given 1,000 free API calls. You can use this to test the service and see if you will be satisfied with the result. You will be provided with a normal token and a Javascript token, but in this case, using the normal token would be sufficient.
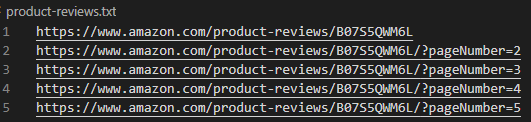
2. A list of Amazon URLs to scrape – I recommend to gather a list of Amazon product review links and save it on a text file with one URL for each line. Name this text file “amazon-products.txt” for the sake of this guide.
3. Nodejs library from ProxyCrawl – Upon signing up, you can freely access the libraries on ProxyCrawl’s website. Just log in to your account and click on the libraries section and look for Nodejs.
4. Node Cheerio Library from Github – Simply go to Github’s website and search for cheeriojs/cheerio
Using Node.js Cheerio+ProxyCrawl
Now that you have everything that we will need for this project. Let us fire up your favorite code editor. For beginners, we recommend using Visual Studio code as it is one of the most popular free source-code editor made by Microsoft that can be used on most Operating systems.
The first thing that we’ll have to do is install ProxyCrawl’s dependency free module and the Cheerio library for Nodejs. This can be done through the terminal by entering the following lines:
- npm i cheerio
- npm i proxycrawl
Once you have successfully installed the library, just create a project folder and a file inside named AmazonScraper.js
Also, make sure to include the amazon-products.txt that you have created earlier inside the project folder. Our project structure should now look like the below example:
To make our code clean and understandable, let’s first declare all the constants in the function scope. In this part, let us utilize the ProxyCrawl node library so we can use the Crawling API as a backbone to our scraper. We also have to include the Node Cheerio library, of course, in order to extract the reviews from the full HTML code of our listed URLs.
const fs = require(‘fs’);
const { ProxyCrawlAPI } = require(‘proxycrawl’);
const cheerio = require(‘cheerio’);
Let us also load up our text file that contains all the URLs that we’re going to scrape as well as the line that will allow us to insert your ProxyCrawl token.
const file = fs.readFileSync(‘product-reviews.txt’);
const urls = file.toString().split(‘\n’);
const api = new ProxyCrawlAPI({ token: ‘Your_token’ });
Now, since we do not want this to just display the results in the console, we have to insert a few more lines so our scraper will automatically send the reviews straight into a CSV file. The function fs.createWriteStream() creates a writable stream with the file path.
const writeStream = fs.createWriteStream(‘Reviews.csv’);
//csv header
writeStream.write(`ProductReview \n \n`);
We will now utilize cheerio for the next part of our code. This is a function that will parse the returned HTML. Cheerio is a fast and flexible implementation of core jQuery which we can use to find the section of user reviews in the Amazon web page and write these reviews into the CSV file.
function parseHtml(html) {
const $ = cheerio.load(html);
const reviews = $(‘.review’);
reviews.each((i, review) => {
const textReview = $(review).find(‘.review-text’).text().replace(/\s\s+/g, ”);
console.log(textReview);
// write the amazon reviews into csv
writeStream.write(`${textReview.replace(/Read more/, ”)} \n \n`);
})
}
For the last part of our code, we will use the setInterval(callback[, delay[, …args]]) from the scheduling timers module. This is an internal construct in Node.js that calls a given function after a certain period. With this, we can set our scraper to do 10 requests each second to the API. This will also allow our scraper to crawl and scrape each of the URLs in our list.
const requestsPerSecond = 10;
var currentIndex = 0;
setInterval(() => {
for (let i = 0; i < requestsPerSecond; i++) {
api.get(urls[currentIndex]).then(response => {
// Make sure the response is success
if (response.statusCode === 200 && response.originalStatus === 200) {
parseHtml(response.body);
} else {
console.log(‘Failed: ‘, response.statusCode, response.originalStatus);
}
});
currentIndex++;
}
}, 1000);
The code will run in a loop until you close or terminate the program, so just add as many URLs as you want into the amazon-products.txt file and the crawler will run through everything and write each of the user reviews it can find into your CSV file.
Notice that each time we crawl a specific URL, the Crawling API will give a response or status code to each of the requests. A successful request will return the value of 200 for pc_status and original_status. Anything else is considered failed and our code should be able to display that in the console log. ProxyCrawl does not charge for failed requests which means only successful requests are counted towards your API consumption.
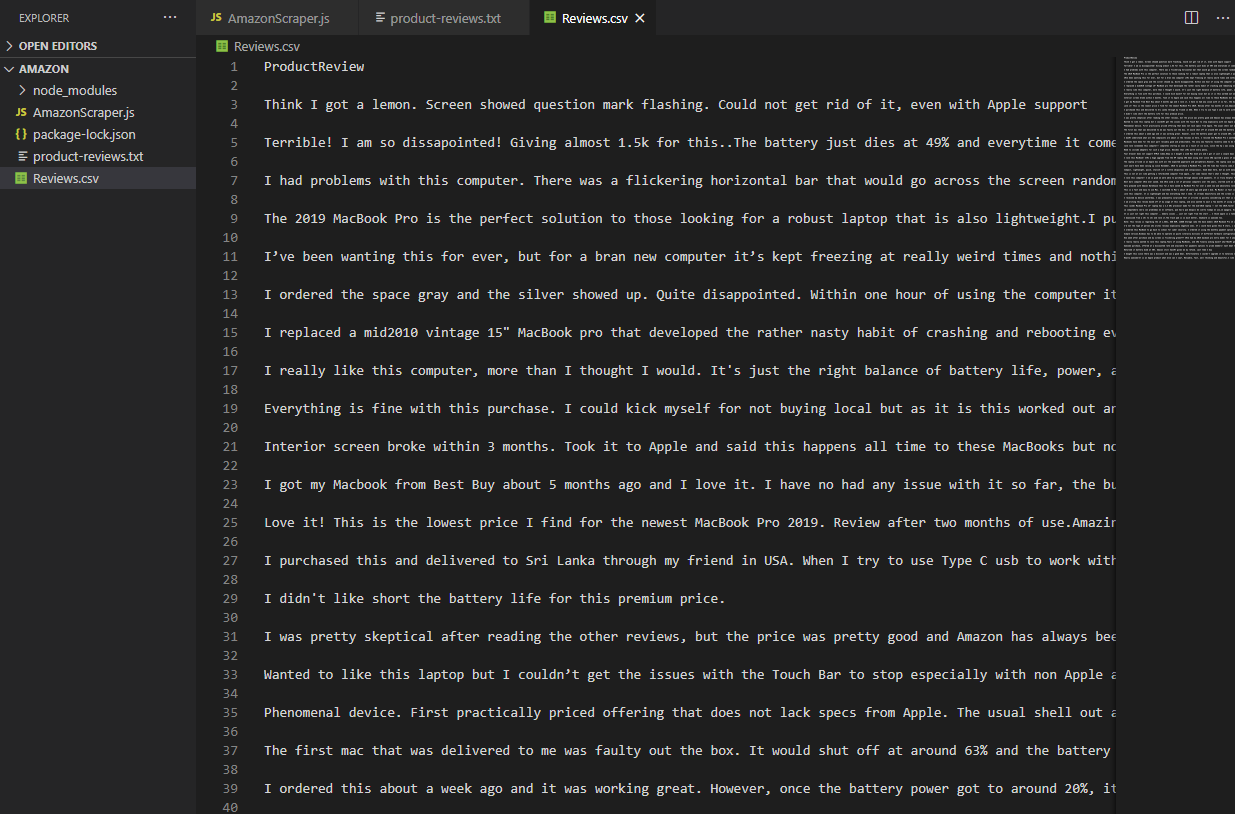
If everything goes well, you will have something like the example below:
Conclusion
Data is all around us and is easily accessible anytime, anywhere, thanks to the World Wide Web. A web scraper is one of the best tools to farm for data and we’ve shown in this article how you can easily build one using ProxyCrawl.
This particular scraper can accept any number of Amazon URLs and as long as the URLs contain a product review, it will be able to get the content and save it to your CSV file. You may also take advantage of the Cheerio library if you wish to extract other values like product price, availability, etc.
Remember, that a scraper can be used on any website and not just Amazon. The Crawling API’s flexibility with the help of the ProxyCrawl libraries will allow its users to make it work with the most popular programming languages today. Integrating it into any existing system is also easy due to the structure of the API.
ProxyCrawl cares about data and our team loves the freedom that the internet provides us. However, we also believe in privacy and that you should still be careful to not abuse this freedom. Scrape responsibly and only scrape publicly available information.
If you want to test our product and see more articles like this, be sure to check our Crawling API and Scraping tools.




Add Comment